Difference between revisions of "2016 Winter Project Week/Projects/ImageRestoration"
| Line 18: | Line 18: | ||
To improve results for large datasets of clinical-quality data, we are investigating restoration methods without training datasets. Here, we are using a patch-based Gaussian Mixture Model approach with MRF priors and utilizing only the current dataset, without an external training dataset. | To improve results for large datasets of clinical-quality data, we are investigating restoration methods without training datasets. Here, we are using a patch-based Gaussian Mixture Model approach with MRF priors and utilizing only the current dataset, without an external training dataset. | ||
| + | |||
| + | <strong>Essentially, we explore a model where for a given location in all volumes of a dataset, we model those image patches as drawn from a particular mixture model.</strong> | ||
{| class="wikitable" | {| class="wikitable" | ||
Revision as of 18:42, 4 January 2016
Home < 2016 Winter Project Week < Projects < ImageRestoration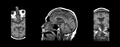
Clinical Stroke Image
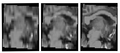
"true" high resolution data


Key Investigators
- Adrian Dalca (MIT)
- Katie Bouman (MIT)
- Polina Golland (MIT)
Project Description
Most synthesis, in-painting or super-resolution methods require a training dataset which includes the desired-quality images. Unfortunately, in the clinical setting this is often now available.
Due to the low quality of clinical images (often with many artifacts, 7mm thick slices, etc), most standard algorithms, such as those for registration, segmentation, analysis, will fail.
To improve results for large datasets of clinical-quality data, we are investigating restoration methods without training datasets. Here, we are using a patch-based Gaussian Mixture Model approach with MRF priors and utilizing only the current dataset, without an external training dataset.
Essentially, we explore a model where for a given location in all volumes of a dataset, we model those image patches as drawn from a particular mixture model.
| Objective | Approach and Plan | Progress and Next Steps |
|---|---|---|
|
|
|