2013 Summer Project Week:WMH Segmentation for Stroke
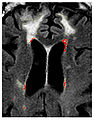
Illustrating the difference between periventricular WMH (red selection) and other hyperintense issue not part of WMH (yellow outline)
T1 images in stroke dataset.
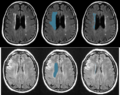
left: FLAIR images, middle: manual delineation of relevant areas, right: manual WMH segmentation.



Key Investigators
- Adrian Dalca, Ramesh Sridharan, Kayhan Batmanghelich, Polina Golland, MIT
- Natalia Rost, Jonathan Rosand, MGH
Project Description
Objective
Following our method developed for segmentation of white matter hyperintensity (WMH) in FLAIR (discussed at the 2013 project week), we are developing methods for detecting regions that present similar to WMH but represent tissue damaged from a previous stroke (chronic stroke) or other processes. These do not have specific shape, but are in general larger and not necessarily periventricular as the WMH tends to be. This dataset is particularly challenging due to the low resolution (1mm x 1mm x 7mm) and with cropped fields of view in the given images.
Approach, Plan
We have a current pipeline for registration of this clinical dataset, and subsequent detection and investigation of WMH patterns..
- Investigate the number and shapes of 'chronic strokes' lesions, as well as the distribution pattern (perhaps to be used a prior in our models below)
- Learn features that can determine
- Solidify a model, currently considering a model with 4 mixture groups.
- Solve and predict using the model (probably a longer goal)
Progress
WMH:
- found a large portion of the stroke data contains chronic stroke lesions, but they vary in shape and size. They consistently seem to be further from periventricular region, they are are least two-slices thick (although not necessarily consistent), but often connected with WMH.
- We devised a generative model for these pixels - 'healthy' tissue, WMH, chronic stroke and acute stroke. Acute stroke is detectable on hyperinstense DWI, while WMH and chronic stroke are together hyperintense in FLAIR. WMH and chronic stroke tissue are then modeled using features involving of voxel intensity, location in relation to ventricles, amount of hyperintense volume in a given spherical region, and perhaps a label similarity count.
Visualization
- one important request with such large datasets is to quickly visualize a subset of the data. During this week we also connected with developeds of XTK and Slicer for improving such visualizations. We also explored the future development of our javascript platform, tipiX, using XTK libraries.
measure volume of hyperintensity in a given radius.